
|
||||
|
3Dゲームファンのためのグラフィックス講座GDC番外編 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
会場:San Jose McEnery Convention Center
GDC2006が開幕した。初日となった21日は、チュートリアル(TUTORIALS)とカテゴライズされた初級セッションのいくつかが執り行なわれた。そのうちの1つ「Advanced Visual Effects with Open GL」を紹介する。
■ Open GL ARBがKhronosグループと統合
Open GLはハードウェアに依存しないオープンプラットフォームなグラフィックスAPIとして、広く活用されているものだ。PCゲームでは「DOOM 3」エンジンがOpen GLベースなのは有名な話だし、プレイステーション3のグラフィックスもOpen GL系のサブセットである「Open GL ES」が正式採用されたことはニュースになった。そう、Open GLは実はゲームとの関係も深いのだ。このセッションでは、そんなOpen GLの最新動向が紹介された。
まず第一のニュースとして語られたのはOpen GLのARB(Architectual Review Board)メンバーがKhronosグループに移管されるというもの。ARBとはOpen GLの標準(拡張)仕様を策定するメンバーで、グラフィックス関連企業やグラフィックス業界のご意見番的な重鎮達から構成される。そしてKhronosはさまざまなデジタルメディアの標準APIを策定しているワーキンググループで、前出のOpen GL ESを策定したことで最近では認知度も高い。2006年3月のARB会議で賛同が得られ、2006年4月のKhronos会議で承認が得られればSIGGRAPH2006でのOpen GL2.1発表以降は、ARBが合流したKhronosグループで後のOpen GLの規格策定が行なわれるようになる。
ARBメンバーとKhronosグループの参加企業がほぼ同じであり、やっていることがほとんど同じで分けていることの意味がなくなってきたということ、Open GLとOpen GL ESにできるだけ最新技術を迅速に反映していこうというのが今回の実質的な統合の理由と思われる。
これにより、KhronosグループはOpen GL、Open GL ES、OpenVG、OpenML、OpenMAX、OpenSL ES、COLLADAの規格策定を行なうワーキンググループとなるのだ。
 |
 |
| 壇上に立ったのはATI ResearchのBill Licea-Kane氏 | Open GL ARBがKhronosに合流 |
 |
 |
| Khronosグループ参加企業一覧 | Khronosグループで取り扱うものにOpen GLが加わった |
■ Open GLとWindows Vistaの最新事情
Windows Vista環境下ではそのGUIのAERO GLASSがD3D9(DirectXのDirect 3D)で制御されることから、D3D9と同種のグラフィックスAPIであるOpen GLは競合してしまうため、Direct 3Dにラッピングされるような形で実装されると発表されてきた。これはWindows Vistaでは「互換性を保つためのつじつま合わせとしてOpen GLをサポートする」という程度の対応であり、Windows VistaではOpen GLのパフォーマンス低下に結びつくと懸念されていたのだ。いわば事実上、Windows VistaではOpen GLベースのゲーム (「Quake」、「DOOM」、etc.)には死刑宣告に近いものがあった。
ところが、これに対しOpen GL支援者から強い要望がマイクロソフトに寄せられ、結果、Windows VistaでもOpen GLがWindows Desktop Managerと共存する形でサポートすることが決定したという。
このことが発表されたときには会場に拍手が起こった。
 |
 |
| Windows Vistaでもネイティヴに近いOpen GL ICD(Installable Client Driver)がサポートされることが明らかに | 「Windows Vista、どうもありがとう」のスライドで会場に拍手が起こった |
(編註:当該記事の内容は発表時のものです。Windows Vistaの最終仕様に関しては個別にご確認ください)
■ Open GLの次期バージョンとその先
~プログラマブルなテクスチャシェイダー、サンプルシェイダー、プリミティブシェイダーとは?
 |
| NVIDIA Michael Gold氏 |
Open GL2.1で変わったところは拡張仕様だったPixel Buffer Objectの標準仕様への昇格、Float Bufferのバリエーション強化、Open GL Shading Language(GLSL) Ver1.20へのバージョンアップ、sRGB色域のテクスチャーのサポート……など。サポートハードウェアは現行のプログラマブルシェーダ3.0仕様(SM3.0)世代GPUであり、大きな技術的なステップアップはない。
続いてその先、Open GL3.0がどうなっていくのかのかが簡単に述べられた。
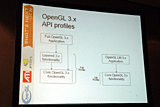
まず、次世代Open GLでは、フルスペックのOpen GLと、その動作対象ハードウェアの機能活用に限定したダイエット版Open GL LMの2弾構成になるという。なお、LMは「Lean and Mean」の略で意訳すれば「必要最低限」といった感じになるだろうか。LMのメリットはソフトウェアの抽象レイヤーが省略され、アプリケーションがハードウェアを直にドライブできる点。これはOpen GL ESのコンセプトとダブっているように思えるが実際、次世代版のOpen GL ESは、このOpen GL LMをベースにした仕様策定が行なわれるという。
 |
 |
 |
| Open GL LMプロファイルが追加される。リアルタイムアプリケーション向けのプロファイルといったところか | プレイステーション 3にも採用されたOpen GL ESはOpen GL LMから策定される | 現行Open GL 2.xのレイヤー構造 |
 |
 |
| Open GL3.xからは“LM”版も策定される | LMのメリットはソフトウェアレイヤーが取り去られてよりダイレクトにドライブできるようになる点 |
3.0を含む2.1以降の次世代Open GLに向けての検討中の仕様も紹介された。
DirectXに採用されている同一3Dモデルの反復描画を高効率に行なうジオメトリインスタンシングの仕組みの導入、GLSLへの32ビット整数のサポートやオフラインコンパイルのサポート(Open GL ESでは導入済み)といった仕様拡張的な話がメインであったが、テクスチャシェーダー、サンプルシェーダなどの新しいシェーダの概念も紹介された。
テクスチャシェイダーはテクスチャユニットの挙動をプログラマブルに仕様拡張するものだ。たとえばテクスチャフィルタリングのメソッドをプログラマブルとしたり、テクセルの取り出しに別の色域への変換処理をかませたりと行なったことを可能にする。
サンプルシェーダーはブレンディング、デプス(深度)処理、ステンシル処理など、レンダリングパイプラインの最後尾であるROP(Rasterize Operation)ユニットにプログラマビリティを導入するものだ。インタラクティブな異方性ブレンディング処理や、より高度なステンシル処理などが可能になるらしい。
テクスチャユニットやROPユニットの挙動は一部のGPUではすでにファームウェアの書き換えレベルでリコンフィギュラブルだったりするがこれをユーザプログラマブルにしようというアイディアと思ってもらっていい。
テクスチャシェーダーとサンプルシェイダーはまだ数世代先のアイディアとのことだが、比較的、近未来のOpen GLに導入されることが決まっているのが、同じく今回紹介されたプリミティブシェイダーだ。
プリミティブシェイダーとは頂点シェイダーとピクセルシェイダーの間の新しいシェイダーステージで、DirectX 10では「ジオメトリシェイダー」という名称で実装が決定しているもの。Open GLではDirectXと同じものでも名前を変える習慣がある(例、DirectXのピクセルシェイダーはOpen GLではフラグメントシェイダー)が、これも読み替えて同じものと思っていい。
プリミティブシェイダーは簡単に言えば、ある頂点に対してプリミティブシェイダープログラムを走らせてその結果に準じた新しい頂点を生成するものだ。たとえば、ファーシェイダーにおいて腕に生やす毛ヒレや、腕をくるむような毛シェルを生成したり、光源を起点にして3Dモデルの輪郭から影ボリュームを生成したりするのに利用できる。
これは、DirectX 10/プログラマブルシェイダー4.0仕様(SM4.0)のGPUが登場したあとのOpen GLにて対応されると予想されている。
 |
 |
 |
| テクスチャシェイダー | サンプルシェイダー | プリミティブシェイダー |
■ NVIDIAがSLIで物理アクセラレーションを行なう技術を発表
午後にはNVIDIAが誇る複数のGPUを1台のシステムで利用してグラフィックサブシステムの高速化を実現するマルチGPUリューション「SLI」(Scalable Link Interface)の最新動向が報告された。
なかでも、注目を集めたのが、SLIで物理シミュレーションをアクセラレーションする技術だ。
 |
 |
| NVIDIA Simon Green氏 | NVIDIA Mark Harris氏 |
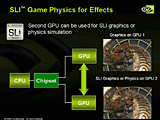 |
| SLI物理の動作概念図 |
この技術では2枚差したビデオカード(GPU)のうち1枚を3Dグラフィックス描画に、1枚を物理アクセラレーションに専念させている。1基のGPUに3Dグラフィックス描画と物理シミュレーションを代わる代わる実行させることも技術的には可能とのことだが、リソースの仕様効率が良くないので今回はそうした実装にはなっていない。
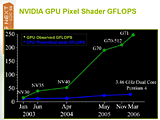
さて、物理シミュレーションはその実装方式にもよるが、大量のデータに対して同じ種類の計算を適用して処理していく、いわゆるデータ並列型のプログラムパラダイムだ。これは並列計算機ライクなGPU向きの処理系であるとして、今回の実装に乗り出したと言うことだ。
 |
 |
 |
| CPUとGPUの演算性能の比較 | 物理シミュレーションは実はGPU向きだった? | |
物理シミュレーションは(1)初動計算、(2)衝突判定、(3)衝突結果の半影の3フェーズに分割できるとし、それぞれをどう実装するかをまずは検討したという。
 |
 |
| GPUに実装できるゲーム物理とは? | ゲーム内物理で一般に実装される剛体物理(Rigid Body Dynamics)はこのような3フェーズに分割できる。それぞれをどうCPU、GPUに処理させるかが問題 |
シーン内に大量のオブジェクトが存在しているとして、それら全てに、ある物理シミュレーションを適用しようとすると、3つのフェーズのうち、全物体の初動計算(位置、加速度など)は、相互依存性がない(というか後のフェーズ任せにするので無視する)のでまさにGPU向けの処理系であり、GPUに簡単に実装できる。
衝突判定はどれがどれに衝突しているのかを判定する部分で、複雑な処理系になるのでGPUでは難しい。SIGGRAPHでは頂点単位の衝突をGPUで検出する論文などが発表されているが、衝突はゲームなどではシーンにかなり依存した処理系になるのでやはりCPUに任せるべきと言うことで、今回の実装ではCPUで処理している。
ということは、初動計算のあとGPU側のビデオメモリの内容をCPU側で読み出すというPCシステムではかなり重く遅い処理系を行なわなければならないが、PCI-Expressバス時代になり帯域が上り下り4GB/secとなって大部改善された点と、そのビデオメモリ読みだしを毎フレーム描画ごとではなく、複数フレーム描画にまたがって低負荷に読み込むようにすれば、まあ何とかなる、という判断をNVIDIAはしたようだ。もちろん毎フレームでないのでズレは出てくるがそこは線形補間したり……といった適当なごまかしを加えるのだろう。
 |
| 「読み出しは悪じゃない」PCI-ExpressではGPUとCPUの高速なデータのやりとりを可能とするのがウリだった。物理シミュレーションでこの恩恵を活用しようというわけだが、実際は毎フレーム物理処理できるほどの帯域はない。だからそれなりの工夫が必要というわけ |
NVIDIAでは、影響を及ぼしあったオブジェクト同士をグループ化して、このグループを1単位として複数グループをGPUに流して処理させる方式を実装した(図参照)。マルチパスレンダリングのように何度かパイプラインを回すことになるだろうが、いずれにせよCPU負荷はないので相対的に見ればアクセラレーションになっているということだ。
 |
 |
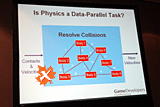 |
| 衝突結果の反映をシーケンシャルに総当たりでやっていたのでは効率が悪い | ||
 |
 |
 |
| 影響を及ぼしたもの同士をグループ化して、これをGPUの複数並列パイプラインにぶち込んで回す |
この一連の処理系は3月9日に発表されたGeForce7900シリーズ用のデモとして公開された「Dino Bones」に実装されている。Dino Bonesは博物館の恐竜の化石展示コーナーを再現したデモだが、石を投げて展示コーナーを破壊することが出来るインタラクティブ機能を持っている。この展示コーナーが投げた石と衝突して崩壊していくアニメーションが、このSLI物理を利用して処理されているのだ。
 |
 |
 |
| NVIDIAの新作デモ「Dino Bones」。破壊の物理シミュレーションはSLI物理処理によって実現されている | ||
 |
| NVIDIAとHAVOKの共同プロジェクト「Havok FX」については追って詳細レポートをお届けする予定 |
これはこのセッションが開催された21日、同日発表の形で発表された。HAVOK FXを採用した3DゲームであればSLIシステムで物理アクセラレーションが効いてパフォーマンスが向上する。実際のHAVOK FXの開発キットのリリースが2006年夏頃とのことなので、実際の採用ゲームタイトルはさらにその後ということになる。物理アクセラレーションハードウェアとして先行発表されたもののなかなかその姿を現わさないAGEIA PhysXカードと、どちらが本当に早く登場するのかがユーザーの立場としては基になるところではある。
GDC2006ではHAVOK FXについての関連セッションがいくつか予定されているのでこれに出席してより詳細な情報を提供したいと思う。
□Game Developers Conference(英語)のホームページ
http://www.gdconf.com/
□Game Developers Conference(日本語)のホームページ
http://japan.gdconf.com/
□関連情報
【3月22日】Game Developers Conference 2006がサンノゼにて開催
任天堂、SCEの基調講演と日本人セッションに注目
http://game.watch.impress.co.jp/docs/20060322/gdc2006.htm
(2006年3月22日)
[Reported by トライゼット 西川善司]
GAME Watchホームページ |
また、弊誌に掲載された写真、文章の転載、使用に関しましては一切お断わりいたします
ウォッチ編集部内GAME Watch担当game-watch@impress.co.jp
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.