
| ||||
|
3DゲームファンのためのGeForce 6800 Ultra講座 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
 |
| GeForce 6800 Ultraカード |
2002年後半から始まったプログラマブルシェーダ2.0世代GPU戦争において、NVIDIAは機能面、性能面において長年のライバルであるATIに後塵を拝す結果となった。この事実をNVIDIA自身が認めることはないだろうが、これは多くの3Dゲームファンおよび3Dゲーム開発者達の間での共通認識となりつつあった。
今回登場した新GeForceには、この状況を逆転させるだけのポテンシャルがあるのだろうか。本稿では、NVIDIAの新たなる切り札、GeForce 6800 Ultraの内部構造の秘密について迫ってみたいと思う。
 |
 |
| 世界中のマスコミ関係者を集め、セミナー形式にGeForce 6を紹介した「NVIDIA EDITOR'S DAY 2004」。その情報量はかなりのものであった | NVIDIA President, CEO and Co-Founder Jen-Hsun Huang氏。今年こそはNVIDIAの名誉挽回なるか |
■ GeForce 6800 UltraはNVIDIAが作った次期RADEON!?
最初に用語の定義の再確認をしておきたい。これまでGPUの世代を語る際、「DirectX 9世代GPU」という言い方をしてきたが、今世代のDirectX 9はリビジョンが細かく更新されてきたため、この表現ではおおざっぱ過ぎてしまう。
3月に開催されたGDCで公開された最新のDirectX 9は「DirectX 9.0c」というリビジョンが設定され、これに含まれるDirect3Dはプログラマブルシェーダ3.0仕様をサポートすることとなった。これをもってDirectX 9.0c世代GPUというのもよいかもしれないが、その仕様が直接イメージしやすい表現として、本稿では2004年度世代の最新GPUをプログラマブルシェーダ3.0世代……これを縮めてシェーダー3.0世代……としてカテゴライズすることにする。なお、先代のNVIDIA GeForce FX、ATI RADEON 9500以上、S3 DeltaChrome、XGI Volariはこれにならい、シェーダ2.x世代と呼ぶことにしたい。
 |
| 新GeForceのスペック概要 |
かつてNVIDIAがGeForce 3を発表したとき、「DirectX 8(シェーダ仕様1.1) = GeForce 3」というアナウンスをしたことがある。今回の発表でNVIDIAは「シェーダ3.0仕様 = GeForce 6」という、あのときと似たアピールを行なっている。このシェーダ3.0仕様について深く掘り下げる前に、GeForce 6の基本情報を整理しておこう。
総トランジスタ数は、信じがたいことにGeForce FX 5950 Ultraの約2倍となる2億2,200万となった。最新PrescottコアのPentium4が1億2,500万トランジスタなので、実にその約2倍の規模のプロセッサと言うことになる。
製造プロセスルールは0.13μm。製造はGeForce 5700系と同じIBMファブで行なわれる。チップサイズは40mm×40mm。BGAフリップチップパッケージを採用する。ビデオメモリは1.1GHz DDR3 SDRAM。ビデオメモリバスはGeForce FX 5950 Ultraと同じ256bit幅。
プログラマブル頂点シェーダユニットは6基を搭載。GeForce FX系のように、内包する用途別浮動小数点実数(FP)演算器リソースをマネージメントして使い回す方式ではなく、完全並列型のアーキテクチャで、いわゆる6パイプライン方式の構成を採用する。演算精度はGeForce FX系と同じ、32bit×4の128bitだ。
プログラマブルピクセルシェーダユニットも同様の進化を果たす。GeForce FX系では、整数ピクセルシェーダ演算器リソース、FPピクセルシェーダ演算器リソースを仮想化した8本のパイプラインでマネージメントして活用するアーキテクチャを採用していたが、GeForce 6では、こちらも完全並列型の16本の独立したパイプライン構成を取る。
こうしてみてくるとわかるが、GeForce 6はGeForce FX系とは根本的に構造が違っている。語弊のある言い方をあえて用いるとすれば、GeForce 6は、イメージ的には「NVIDIAが作った次期RADEON 9800」的なものになっている。
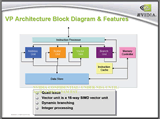
また、GeForce 6は、コンシューマ向けGPUとしては初めてプログラマブルなビデオプロセッサ(PVP)を内蔵する。これは、動画像のデコードはもちろん、エンコードをもアクセラレーション可能なプロセッサだ。
ハードウェアMPEGエンコーダ内蔵のビデオキャプチャーカードは、PCユーザーにはなじみ深いものだと思うが、そのハードウェアMPEGエンコーダ部分がプログラマブル仕様でGeForce 6に内蔵されていると考えればよい。プログラマブルとはどういうことかというと、MPEG-2だけでなく、MPEG-1、MPEG-4、WMV9、DivXなどのエンコーディングも、対応するエンコーダを用意することで対応できると言うことだ。
かつてATIがRADEON 9700発表時、プログラマブルピクセルシェーダを活用して動画処理を行なうソリューションを提示したが、NVIDIA GeForce 6では専用のハードウェアユニットでこれを行なう。GeForce 6のPVPがアクセラレーションできるエンコード処理は入力映像に対する「色圧縮」、「ノイズ除去」、「3-2プルダウンプログレッシブ化処理」と、予測フレーム生成の際の「逆離散コサイン変換」、実エンコード処理における「動き予測処理」と「動き補償処理」など。
なお、入力映像の「離散コサイン変換」は依然CPUで行なうので、「完全なCPUフリーなハードウェアエンコーダ」ではない。テレビ録画PCを実現するためのものというよりは、DVカメラからのDV映像のMPEGエンコードや、デジタルビデオデータの加工用のために設けられた機能、という印象だ。ちなみにNVIDIAは、近い将来、GeForce 6のPVPを活用したAdobeの「After Effects」用のプラグインソフトの提供の可能性を示唆している。
 |
 |
| プログラマブルなビデオプロセッサを内蔵するGeForce 6。動画エンコードのアクセラレーションに貢献 | チップの写真。ダイサイズはかなり大きい。さすがは0.13μmプロセスルールでトランジスタを2億も詰め込んだだけはある |
■ 頂点シェーダでディスプレースメントマッピングを行なう
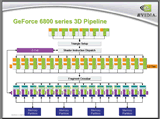 |
| GeForce 6800 Ultraのブロックダイアグラム |
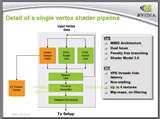 |
| 頂点シェーダユニットの中身。上の全体ブロック図の最上段部の1ユニットの拡大図だと思って欲しい。VPEはVertex Processing Engine、VTFはVertex Texture Fetchを意味する |
シェーダ3.0仕様ではプログラマブル頂点シェーダがテクスチャ参照機能を持つようになった。これが最大の特徴だ。
「テクスチャとはポリゴンに貼り付ける画像」という概念が強いが、実はプログラマブルシェーダ時代においては、ベクトルデータを入れ込んだ汎用数値テーブル的な活用のされ方が一般化している。たとえば「バンプマッピング」として知られる、ポリゴンに凹凸を貼り付ける技術も、凹凸をポリゴンに見立てた「バーチャルなポリゴン」の法線ベクトル(面の向きを表す)をいれこんだテクスチャ(法線マップ)を用い、ピクセル単位で陰影処理を行なうことで、“見かけ上だけ”の凹凸を表現している。
「ベクトルデータを入れ込んだテクスチャが一般化しているのであれば、これが頂点シェーダで利用できてもいいではないか」……そんな発想の流れで登場したのが、この「頂点シェーダがテクスチャにアクセスできるアイディア」だ。
このアイディアの一番単純な応用例は、今処理している頂点データをテクスチャから読み出したベクトルデータを用いて変位(Displacement)させてしまう例だ。たとえば、基本的な粘土細工の人体形状モデルを用意したとする。これをオオカミ男に加工したり、マッチョなスーパーヒーローに加工するためには、へらで削ったり、あるいは粘土をさらに盛りつけて肉付けをしたりすることになる。この「へらで削る」「肉付けする」といった概念に相当するパラメータをテクスチャで用意しておき、これをレンダリング時に頂点シェーダで考慮すれば、目的の形状に変位させることができる。こうしたことがGeForce 6(プログラマブル頂点シェーダ3.0)で行なえるようになるのだ。
こうした処理系を「頂点テクスチャリング」あるいは「ディスプレースメント・マッピング」と呼ぶ。
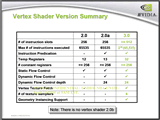 |
| プログラマブル頂点シェーダ3.0の仕様内容。GeForce 6のプログラマブル頂点シェーダはこの仕様を満たす |
この他、頂点シェーダのテクスチャアクセス機能は、もっと単純に、テクスチャを定数領域として活用する応用形態も考えられる。人体などの可動する3Dキャラクタはボーンと呼ばれる骨組みを元にアクションを形成していくが、このボーンスキニング処理の際に必要な外皮とボーンの関係を表す情報は、これまでGPUの定数領域に入れていた。複雑なボーンスキニング処理をやりたくても、GPUの定数領域により制限されていたのだ。GeForce 6世代では、この情報をテクスチャに入れておくことで、より複雑でリアルなアクション表現が可能になる。そう、いってみれば、テクスチャを頂点シェーダの汎用メモリとして活用するわけだ。
テクスチャ読み込みは従属読み込みにも対応。読み込み可能な枚数は最大4枚まで。各頂点シェーダのテクスチャフェッチ(読み込み)ユニットにはL1テクスチャキャッシュが内包され、さらに全頂点シェーダユニットで共有されるL2テクスチャキャッシュも内蔵するという非常に贅沢な構成になっている。
テクスチャはMIPMAPに対応し、MIPMAPレベルを指定してからのアクセスになる。また残念ながらテクスチャフィルタリングはサポートされない。よって、ジオメトリ解像度とテクスチャ解像度がミスマッチしている場合には、ポッピング(頂点が微妙に揺れてキャラクタの形状がふくらんだりへこんだりする様子)が発生する危険性がある。
この他、GeForce 6のプログラマブル頂点シェーダの各基に動的条件分岐やサブルーチンコールの分岐処理ユニットが内蔵される。
 |
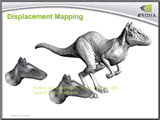 |
| NVDIAのGeForce 6用ディスプレースメント・マッピング実演デモ。視点からの距離に応じて、大きな波はディスプレースメント・マッピングで表現され、小さな波はバンプマッピングで表現される | 凹凸をピクセルシェーダーのフェイクで表現するのがバンプマッピング。実際に凹凸のジオメトリがポリゴン面に生成されるのがディスプレースメント・マッピング。ただし、GeForce 6のディスプレースメント・マッピングはそのままでは頂点が増えないのでその取り扱いはなかなか難しい |
■ GeForce 6は今回もテッセレータユニットの搭載はなし
 |
| NVIDIA Vice President of Technical Marketing Tony Tamasi氏 |
 |
| NVIDIA Chief Scientist David Kirk博士 |
RADEON 9500以上やPerhelia系では、視点からの距離などに比例したポリゴン分割を行なう仕組みである「テッセレータ」を内蔵していたが、今回のGeForce 6でも、これを内蔵していないのである。
「ジオメトリが増減するテッセレーションのしくみについては、ハードウェア・テッセレータではなくプログラマブルシェーダのソフトウェア的なアプローチで行なう」(Tony Tamasi氏)
去年、GeForce 5900 Ultra発表時に、NVIDIAのGeForce設計の舵取りをしているDavid Kirk博士にテッセレータユニット搭載の可否について伺った際、「テッセレータの動作は制御が難しく、その搭載は時期尚早だと考えている」という返答を頂いた。あのときの発言は今世代のGPUでも生き続けていることが伺える。
そのNVIDIAのいう、ソフトウェアアプローチのテッセレーションの仕組みについても簡単に解説しておこう。
基本的な概念としては、OpenGL 1.5、DirectX 9.0c、Xboxにある頂点バッファレンダリング(Render to Vertex Buffer)という技術があり、これを活用する方針になる。
まず、頂点情報を頂点シェーダからピクセルシェーダに出力。ピクセルシェーダはこの情報を元に、入力された各頂点の法線ベクトルを補間するように、新たな頂点を算術合成してこれをフレームバッファに書き込む(レンダリングする)。ピクセルシェーダが頂点をレンダリング……というイメージが掴みにくいかもしれないが、“ピクセル”シェーダといっても、ここではもはやピクセル陰影処理を計算する目的ではなく、単なる汎用浮動小数点実数(FP)演算器として活用しているのだ。できあがったバッファを新たな頂点ストリームとして頂点シェーダに入れてやれば、結果としてテッセレーションが行なわれた映像が得られる……というわけだ。
なお、「こうすればできる」と言いつつも、この技術を使ったデモは今回の発表では示されておらず、結局のところ「あまり実用的でない」という感触はぬぐいきれない。いずれにせよ、テッセレータユニットの実装を来世代以降に持ち越す決断をしたことには変わりない。
■ 贅沢なピクセルシェーダユニット構成 ~その数はRADEON 9800 XTの4倍
ピクセルレンダリングパイプラインは仮想化なしの16本。これはRADEON 9800 XTの2倍に相当する贅沢な構成だ。
全体のブロック図を見るとわかるが、ピクセルレンダリングパイプラインは、「Fragment Crossbar」を境に上がピクセルシェーダユニット群と、下がラスタライズユニット群に分かれた構成になっている。
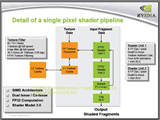 |
| 前出の全体ブロックなかの中断部のパイプラインを拡大したもの。ここでは主にテクスチャ読み出しと実際のピクセル単位の陰影処理が行なわれる |
GeForce 6もGeForce FX同様、演算精度は32bit(FP32)×4の128bit精度を採用する。
ピクセルシェーダユニットの強化はすさまじく、注目すべき点はいくつもある。1点はシェーダユニットが2基ある点だ。各パイプラインに2基ずつあるので、数だけの比較でいけば32個あることになり、RADEON 9800 XTの4倍の数と言うことになる。
2基構成のシェーダユニットのうち、1基はテクスチャ処理ユニットとペアリング動作する関係でテクスチャアドレッシング機能を持ち、FP16(16bit浮動小数点実数)の正規化専用演算器を持つが、それ以外の機能は両者は同じ128bitFP(FP32×4)SIMD演算機能を持つ。注目すべきは、この2つのFPシェーダユニットがスーパースカラ(並列同時)動作できることにある。具体的に言えば、2つの命令間に依存関係がなければ、同時に2命令を実行可能なのだ。
 |
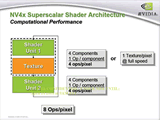 |
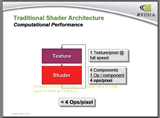
| RADEON 9500以上の場合。テクスチャユニットとシェーダユニットがシーケンシャルな動作を繰り返すだけ | テクスチャユニットがテクスチャリングを行なわなかった場合は、2つのシェーダが並列同時動作できる |
とはいえ、シェーダ1ユニットがテクスチャ読み出しを行なった場合は、128bitFP演算器としては機能できないので、一般的なテクスチャリング主体のレンダリングでは、このアーキテクチャのアドバンテージは出ない。長いシェーダを実行して初めて生きてくる構成だ。
テクスチャユニットもなかなか贅沢な作りになっており、テクスチャキャッシュはL1キャッシュを各パイプラインが自身専用のものを持ち、L2キャッシュを共有する形になっている。パフォーマンスも申し分なく、4点サンプリング(4TAP)のバイリニアフィルタリングまでであれば、“パフォーマンス落ちなし”でフルスピード動作できる。「見栄えは良くしたいがパフォーマンス落ちはいやだ」という3Dゲームファンは、テクスチャフィルタリングを「バイリニア固定」設定にしておくといいだろう。これはGeForce 6ユーザーとなる予定の人は覚えておいて損はないTIPSだと思う。
そして、地味だが3Dグラフィックステクノロジーにおいて大きなステップアップといえるのが、ついにGeForce 6ではFP16テクスチャの汎用性が32bit整数カラーと同じになったということだ。テクスチャフィルタリングはバイリニア、トライリニア、異方性の全てが使え、αブレンディングもサポートされる。演算処理にもパフォーマンス低下はなく、唯一弱点があるとすれば、32bitカラーに比べ、同解像度で倍のビデオメモリ容量とビデオメモリバンドを消費すると言うことだけだ(ARGB全てが16bit幅で1ピクセル64bit幅となるため)。
これに併せて、GeForce FX系ではDirectX環境下でFPテクスチャやFPフレームバッファを使うことができなかった制約が、ついに取り払われた。これにより、GeForce FX世代では回りくどい方法でしか実現できなかった「ハイダイナミックレンジ(HDR)レンダリング」も、RADEON 9500以上と同様にできるようになったわけだ。FP16バッファであれば、フィルタリングやブレンディングに制限がないぶん、RADEON 9500以上にHDRレンダリングでできることの幅が広がったと言える。
皮肉なことだが、かつてRADEON 9800 XT発表時に「HalfLife 2」開発元のValve代表が発言した「『HalfLife 2』はRADEON 9500以上でないと辛い」という理由は、その発売前に改善されてしまったことになる。
そして、もう1つ注目すべきなのは、ついにプログラマブルピクセルシェーダに条件分岐、サブルーチンコールがサポートされた点だ。図中の「BRANCH PROCESSOR」がその機能を担当する。このサポートにより、1つの長いシェーダで、シーンの状況に応じた様々な材質を再現するものができるようになるのだ。
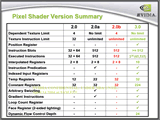 |
 |
| プログラマブルピクセルシェーダ3.0(GeForce 6)と2.x世代以前の仕様比較 | NVIDIAがGeForce 6用に発表したデモ。人魚の肌と鱗は、条件分岐を駆使した単一のシェーダーによって表現されている |
■ UltraShadowII機能で「DOOM 3」の影生成が2倍高速に! ~4つのMRTに対応してRADEONとの格差が消滅
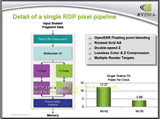 |
| 前出の全体ブロック図の中の最下段のパイプラインの中のユニットを拡大したのがこの図 |
なぜ16本のパイプラインがここで上下に一度断ち切れているのだろうか。
これは各ピクセルシェーダユニットがMRT(Multi Render Target:マルチ・レンダー・ターゲット)をサポートしたことに関係している。MRTとは1パスで複数のバッファやテクスチャにレンダリングする仕組みのことだ。GeForce 6では、ついに4つまでのMRTがサポートされ、RADEON 9500シリーズ以上との機能格差がやっと消滅した。
MRTでは、いわば1本のパイプラインからの出力として複数のROPユニットを使うケースが考えられるため、「Fragment Crossbar」より下は各パイプラインで共通リソース化して使う仕組みを採用したのだと思われる。
ちなみに、MRTを使わないケースでは、各パイプラインが必ず1個のROPユニットを使えるので、16本のパイプラインが専用のROPユニットを活用するように見える。逆にMRTを活用した場合はROPユニットがパイプラインの本数に対して不足するので、ROPユニットに空きが出るまでパイプラインストールが発生し、パフォーマンス低下が起こる。が、この辺りはMRTの使用頻度とのトレードオフという形でこのような設計を採用したと思われる。
なお、各ROPユニットはZ値(深度値)処理ユニットとカラー処理ユニットがあり、後者のカラー処理ユニットは、Z値処理ユニットとしても活用できるのがGeForce 6の特徴だ。
ROP処理ユニットが、デュアルZ処理ユニットとなって何がうれしいか。これは、影生成の際の、ステンシルシャドウボリューム技法のレンダリングに効いてくるのである。
 |
| 影生成にステンシルシャドウボリューム技法を採用した3Dゲームとして知られるid softwareの「DOOM 3」。2004年7月発売予定とのことだが…… |
この影領域のレンダリングの際、論理的に影領域にならないと判定できる場合は、その処理を省略する。ここまでが、GeForce FX 5900 Ultraに搭載されていたUltraShadow機能だ。
さて、この影領域のレンダリング工程はまさにZ値処理に相当する。Z値処理ユニットがデュアル動作できるGeForce 6800は、この処理を2倍高速にこなせるというわけだ。この性能向上をNVIDIAは「UltraShadowII」機能と命名している。
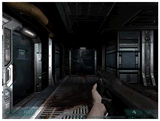 |
 |
 |
| 「DOOM 3」のとある1シーンより | UltraShadowIIを使わずに陰影処理と影生成処理を行なった場合の、影領域を可視化したときの映像 | UltraShadowIIを使って陰影処理と影生成処理を行なった場合の、影領域を可視化したときの映像。余計な影領域の生成処理が少なくて済む |
■ HDRレンダリングに本気に対応したGeForce 6
最後にGeForce 6のHDRレンダリング関連の特殊機能について解説しておこう。NVIDIAは3Dゲームグラフィックスに代表されるリアルタイム3Dグラフィックスにおいても、HDRレンダリングを積極的に導入すべきだと主張する。
HDRレンダリングとは、1,677万色に制限されない、現実世界のような幅広い(ハイダイナミックレンジな)暗さから明るさに配慮した陰影処理を行なおうというものだ。
なお、ディスプレイの表現色は1,677万色になっているため、最終的には限られた色数で映像を見ることにはなる。とはいえ、初めから限られた色数でレンダリングしてしまうと値が飽和し、物理量として正しい結果にならない。人間は、現実世界において、とてつもなく明るい空間や暗い空間に行くことがあるが、その場合、瞳の絞りを変えて適正な明るさで世界を見ている。これと同じ理屈で、3D世界を正しい物理量でレンダリングして、表示する際に色数を1,677万色に丸めよう……というのが広義としてのHDRレンダリングの意味になっている。
さて、NVIDIAは、このHDRレンダリングにおいて、陰影演算こそFP32で行なうものの、演算結果の格納はFP16で十分とし、GeForce 6では、これを標準の汎用バッファとして強く推奨していくようだ。余談ではあるが3DCGアニメ「ファインディング・ニモ」や「トイ・ストーリー」を制作したPIXARスタジオも同様のアプローチを取っている。
この方針実践のため、GeForce 6では、FP16バッファ/テクスチャに関しては、制限一切なしのテクスチャフィルタリング、αブレンディング、アンチエリアスをサポートし、いわゆる整数32bitカラーモードと全く同じ同等に扱えるようにしてしまったのである。
そして、GeForce 6のサポートするFP16バッファ・フォーマットは、「スターウォーズ」の監督として知られるジョージ・ルーカス率いるILM/Lucas Digitalが提唱するOpenEXRフォーマットに準拠したものになっている。
これまで、HDRレンダリングは、その内容を1,677万色に落とし込むトーンマッピング処理をピクセルシェーダで構成しなければならなかったが、GeForce 6の場合は、OpenEXRバッファに限ってはそのままハードウェア側でトーンマッピングを行なってダイレクトにディスプレイに出力できる。たとえるならば、RAMDACがFP16バッファに対応した……というようなイメージだろうか。
もちろん、ユーザーが用意したトーンマッピング・シェーダを使って1,677万色に丸め込むこともできるが、よほど特別な理由がない限りは、GeForce 6のネイティブ機能を利用すべきだろう。
なお、NVIDIAは、「ハイエンドゲームエンジンは、早ければ2004年末までに、OpenEXRベースになると思う」と強気な予想を述べている。
 |
 |
| OpenEXRベースでレンダリングを行なうGeForce 6用デモ。まるで短編映画のような内容になっているデモ。このクオリティの映像がリアルタイムで動く | |
■ 3DMark03は12,000を超える ~GeForce復活神話が始まるのか!?
 |
| 3DMark03でこのスコアは確かにすごい |
RADEON 9800系と比較して機能面での弱い点を強いて挙げるとすれば、テッセレータの搭載を今回も見送った点……あたりだろうか。ただ、テッセレータを活用したアプリケーションがここ1年では結局登場してこなかったので、この点がユーザーにとって不利に働くことはないと思われる。
なお、ベンチマーク結果はいずれ各所から報告されると思うが、NVIDIAからの資料では3DMark03のスコアで12,000を超えると発表された。これはRADEON 9800 XTの約2倍の値になる。これまで3DMark03に異議申し立てをしたり、新GeForce FXがリリースされてもほとんどそのスコアが伸びなかったりと、NVIDIAにとって3DMark03はかなり鬼門な存在だったわけだが、今回はこれだけのスペックをひっさげてきただけあり、さすがに鼻息が荒い。
機能面、性能面でかなり強力なGeForce 6だが、問題点もあるにはある。
1つは消費電力の問題だ。電源コネクタを2つも使用し、Pentium 4クラスのCPUと組み合わせた場合には、400W電源ユニットでは電力不足に陥る……という報告もあるほどだ。
そしてダイサイズが巨大な2億2,200万トランジスタのビッグチップを搭載したビデオカード製品が一体いくらになるのか……ということも気になる。
製品ラインナップとしては、「GeForce 6800 Ultra」とその下位モデルとなる「GeForce 6800」の存在が明らかになっているが、両者はパイプライン数の違いがある。具体的にはGeForce 6800 Ultraが16本,GeForce 6800が12本となる。
また、そのさらに下位モデルのラインナップについての具体的なアナウンスはなかったものの、「今回のGeForce 6アーキテクチャのスケーラビリティはわかりやすいはずだ」としていることから、頂点シェーダの数をたとえば4個、2個、ピクセルレンダリングパイプラインを8本、4本として削減した下位モデルが後に登場してくると思われる。なお、今回発表されたGeForce 6800シリーズの実際の製品リリースは5月以降といわれている。リテール価格は未定だ。
2003年は圧倒的優位のまま逃げ切ったATIだが、NVIDIAの反撃に対する術はあるのだろうか。なお、ATIも近々、新GPUの発表を行なうと見られており、今年も昨年同様の、NVIDIA対ATIの白熱したGPU戦争が見られそうだ。
 |
 |
| リファレンスカードの表と裏。電源コネクタが2基あるがこれは飾りではなく、本当に2系統の電源入力を必要とする | |
□NVIDIAのホームページ
http://www.nvidia.com/
□OpenEXRのページ
http://www.openexr.com/
□関連情報
【3月26日】NVIDIA、次期GeForce(NV40)にて
プログラマブルシェーダー3.0の実動デモを公開
http://game.watch.impress.co.jp/docs/20040326/nvidia.htm
(2004年4月15日)
[Reported by トライゼット西川善司]
GAME Watchホームページ |
また、弊誌に掲載された写真、文章の無許諾での転載、使用に関しましては一切お断わりいたします
ウォッチ編集部内GAME Watch担当game-watch@impress.co.jp
Copyright (c) 2004 Impress Corporation All rights reserved.
|
|