
|
||||
|
Game Developers Conference 2007現地レポート
3Dゲームファンのための「DirectX 11」講座~GDC2007特別編~ |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
| サンフランシスコで開催されたGDC2007 |
会場:Moscone Convention Center
■ DirectX 11以降の進化方針
 |
| DirectX 11進化の方向性 |
そのアップグレード方針は、前回のDirectX 10.1の所で触れたものと同じ
-
(1)さらなる映像品質の向上
(2)柔軟性の向上
-
(3)プロシージャルコンテンツ生成を可能にする機能
(4)動的なクオリティ対パフォーマンスのスケーリング機能
(5)ハードウェアの新機能サポート
以下は、どの話題が(1)~(5)のどれに対応するかという対応がわかりにくいのだが、Boyd氏のプレゼンテーションに従って、彼の語ったDirectX 11以降のDirectXの姿について見ていきたいと思う。
現在、DirectX 11以降において計画検討されている機能としては「コマンドバッファ生成(Command Buffer Creation)」がある。
これは、CPU側で描画コマンドを成形してGPUへと送り、それらをGPUで実際に描画していく……という現在のCPU→GPUパイプラインだけでなく、ある程度、自発的にGPU側だけで実行していける仕組みを導入しようという提案だ。
例えば、反復的に実行されるGPU処理をマクロのような形でGPUサブシステム側に予め登録しておき、実際の描画時には「どのマクロを実行しろ」というトリガを送るだけで描画ができるようになる。CPU→GPUのバス消費を低減できパフォーマンス向上に貢献できるわけだ。
これは丁度、GPUに実行させるコマンドリストをメインメモリ上に作り込んでおいて、これを必要なときにGPUに実行させるXboxシリーズ特有のPush Buffer機能の発想に近いものになる。Xboxシリーズではビデオメモリとメインメモリが同一空間にあるので、比較的リーズナブルに実現できた機能だが、PCの場合はどのように実装していくのかが注目される。
また、マルチコアCPUが当たり前になってきている昨今では、DirectX 11以降では積極的なマルチコアCPU活用が必要になるだろうとBoyd氏は語る。GPUの仕事に必要な様々なリソースをマルチコアCPUで効率よく準備し、GPUを待たせない仕組みの実装が必要になると言うことだ。
 |
 |
| DirectX 11以降の新フィーチャーは? | マイクロソフト、ソフトウェアアーキテクト、Windowsグラフィックス、Chas Boyd氏。同氏は3年ほど前、マイクロソフトを退社して自身のゲームスタジオ設立などを行なっていたが、最近、マイクロソフトの同一ポジションに復職した |
■ DirectX 11以降、GPUはストリーミング・プロセッサのポテンシャルを身につける
 |
| GPUをより一層汎用化したストリーミングプロセッサとして活用するために |
GPUは、ハードウェア的視点で見れば「ベクトル演算器をたくさん実装したプロセッサ」であり、グラフィックス処理はコンピューティングパラダイムとして見ると「大量のベクトルデータのストリーミング処理」に相当する。
「大量のデータをベクトル演算器アレイで処理していく」という仕組みは、ビデオプロセッサやDSPのようなストリーミング・プロセッサとよく似ているわけだが、やはりGPUはグラフィックス処理に特化したプロセッサなので、その目的に特化したクセのある設計になっている。
DirectX 11世代では、そうした「クセ」を低減し汎用性を持たせ、GPUをより汎用のストリーミングプロセッサとして使いやすくしようとしているというのだ。
具体的には、処理に流し込めるベクトルデータの配列構造をより柔軟にし、複数のストリーム出力を行なえて、さらには演算結果をどの出力ストリームに出力するかまでを柔軟にスイッチングできるような仕組みなどを検討しているという。
シェーダユニットそのものの機能拡張も、もちろん予定されている。
命令セットで言えばブレンディングに二進論理演算の仕組みまでを導入したり、計算結果を線形値から任意の非線形カーブで変換した値にする機能、モジュール化された複数のシェーダをリンクして1つのシェーダとして活用できる機能、ハードウェアレベルでのデバッグ機能などの導入について議論されている。
また、DirectX 11以降では10.1の時以上にGPGPU向けの強化も行なわれることになるようだ。
最大演算精度は現行の32ビット浮動小数点(FP32)の単精度から、64ビット浮動小数点(FP64)の倍精度に拡張されることは間違いないだろうという。ただし、最初の世代ではオプション扱いとなったり、サポートはされてもパフォーマンス的には遅かったり……といった制限事項が付く場合もあるだろうとのこと。
この他、GPGPUのために、メモリアクセスの高速化についてさらに突き止めていく必要があるとしている。
グラフィックス処理の場合は、大半のメモリアクセスを占めるテクスチャアクセスにおいて、ある程度そのアクセス先の局所性が期待できる。ところがGPGPUの場合は、メモリアクセスにランダム制が強く表れるために、現在のGPUのキャッシュシステムでは対応しきれないケースが多い。現在のGPUに特化しているキャッシュシステムなどの汎用用途向けへの改善は、このDirectX 11以降の世代では必須になるというわけだ。なお、GPUの仮想化が進み、マルチスレッディングが当たり前になると、複数のGPGPUアプリやグラフィックス処理が並列に動作するようになってくる。そうなれば、ビデオメモリの実装容量はさらに増えることになるだろうと予測されている。現在では1カードで768MBものビデオメモリを搭載したカードなどが登場してきているが、DirectX 11以降の世代ではおそらく数GBのオーダーになっていることだろう。
こうしてみてくると、DirectX 11世代のシェーダユニットの拡張は、グラフィックス処理用の命令充実というよりは、より汎用のベクトルプロセッサとしてのポテンシャルを高めるためのもの……ということが伝わってくる。
 |
 |
| シェーダユニットの進化の方向性 | |
■ 次世代のテクスチャ管理システムは?
 |
| コンテンツ生成 |
現在、テクスチャはアーティストによってハンドペイントされるケースが多く、3Dグラフィックスそのものの高解像度化もあって、そのテクスチャの解像度は2,048×2,048テクセルから4,096×4,096テクセルにまで増加しつつある。実現までの道のりは長期的な話にはなるだろうが、できるものについてはテクスチャはプロシージャル生成していくアプローチが必要になるだろうという。
また、テクスチャ管理についても、テクスチャサイズが大きくなりつつある昨今では洗練された手法が必要になってくるだろうとしている。その1つとして実装が検討されているのがインテリジェントなテクスチャ・ローディングシステムだ。現在の3Dグラフィックスパイプラインではアプリケーション側がレンダリングの際に必要なテクスチャをビデオメモリに予め読み込んでおくような段取りが不可欠だが、これはビデオメモリ利用効率の面で考えるとあまり望ましくない。
そこで、テクスチャ読み込みの仕組みを実際にレンダリングに必要なときにその都度読み込まれるようにし、またMIP-MAPも必要なときに必要なレベルのものまでを生成するというかんじのシステムを考案中だという。なお、読み込みをホストに知らせるようなハードウェア的な支援がGPUに必要だし、動的読み込みを行なったがために描画フレームレートの不均一化が起こってしまってはその価値が半減してしまう。そのため、その実装は一筋縄ではいかなそうだ。
まぁ、大規模なデータを処理するようなGPGPU用途では、一定したパフォーマンスよりもメモリ管理の難しさの方がネックになることが多いので、そうした用途では、この機能は歓迎されることだろう。
この他、テクスチャ圧縮についても次世代メソッドの検討が開始されているという。例えば、マイクロソソフトDirectXテクスチャ圧縮として知られるDXTを、より発展進化させてHDRテクスチャ圧縮を実現したりといったことは急務だとされている。
 |
 |
| テクスチャ管理 | テクスチャ圧縮 |
■ 3Dモデル処理に対する新しいパイプラインの投入
 |
| テッセレーション |
 |
| 新たな3Dモデル処理パイプラインの形? |
適当な解像度の3DモデルをGPUに入れておき、これを視点からの距離に応じて自動的にポリゴン分割を行ない、動的に多ポリゴンモデル化する仕組みは、映画用CGなどのオフラインレンダリングではかなり実践導入されている手法だが、Boyd氏はリアルタイムグラフィックスにおいても今後はこの仕組みが重要なテーマになると指摘する。
具体的には、まず、GPUにはベースとなる3DモデルをGPUに転送しておき、これを任意のポーズ変形しつつ同時にポリゴン分割(テッセレーション:Tessellation)を行なって視線からの位置に妥当なポリゴン数のモデルに増幅する(Patch)。最後に、ディテール部を、こちらも視線からの距離に適したレベルで、ディスプレースメントマッピングでジオメトリレベルで加工したり(Triangle)、あるいはフェイクな微細凹凸として法線マップを適用したりする(Pixel Fragment)。
ただ、このタイプの技術のメインストリーム化は意外に難しい。これまでにも何度かこれと似たような仕組みが提案されてきたがそのたびに失敗してきている。
まず、問題なのは、こうした仕組みと適合するアート制作においても新たな標準化が必要になってくるという点。3Dグラフィックスツール(DCCツール)側が、前述したような多ポリゴンモデルから低ポリゴンモデルとディテールテクスチャ(ディスプレースメントマッピングと法線マップ用)のデータ制作をサポートしてくれなければならないし、そもそも、低ポリゴンモデルのデータ形式についても何らかの標準フォーマットを定義する必要があるだろう。
また、ポリゴン分割手法は法線補完形式に分割するのか、あるいはベジェ/Bスプライン曲線で制御してポリゴンを生成するのか、またその分割レベルをどう与えればいいのかといった部分にも新しい標準化が必要になる。
■ テッセレータはプログラマブルシェーダの形ではなく固定機能ユニットになる?
また、事実上、新しいレンダリングパイプラインが形成されることになるので、GPUのハードウェアレベルにおいても、新しいプログラマブルシェーダのステージを新設する必要が出てくるだろう。DirectX 10で採用された第三のプログラマブルシェーダは、その実装まで、最初の2つのプログラマブルシェーダの登場(2001年)から実に6年の年月をかけてやっと新設されたくらいだ。新シェーダステージの導入には業界は慎重な態度をとることは間違いない。
 |
 |
| テッセレーションとディスプレースメントマッピング | |
ディスプレースメントマッピングについても、現在、2通りのメソッドが出てきており、どちらが主流になるか、あるいは両方の標準化を進めるべきなのかの議論も重要になってくる。
1つは希望する形状にポリゴンを増幅して変形させる方法で、もう1つはポリゴン柱を突き立ててその中をローカルなレイトレーシングを実行する(ボリュームレンダリングをする)方法だ。前者はポリゴン分割精度をどの当たりに落とし込むのかといった議論が必要になり、後者についてはピクセルシェーダ負荷が高くなり、MSAAとの相性や影生成アルゴリズム、早期Zカリングアルゴリズムとの親和性がよくないという点も改善しなければならない。
 |
 |
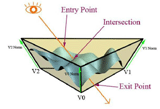 |
| ディスプレースメントマッピングなし。DirectX 10 SDKのサンプルより | ディスプレースメントマッピングあり | 凹凸を新設したい箇所にポリゴン柱をジオメトリシェーダで作り出し、この四角柱の中に含まれるディテールについてローカルなレイトレーシングを行なう |
多ポリゴン化のためのポリゴン分割を行なったり、あるいはジオメトリレベルでのディスプレースメントマッピングを行なうのに活躍するテッセレータの実装については、現時点では固定機能としてのテッセレータを考えているという。このテッセレータユニットはレンダリングパイプラインの新ステージとして新設定義され、プログラマブルシェーダではないもののベジェ、Bスプライン、Catmull-Clarkといった様々なテッセレーションアルゴリズムをサポートするものとする。
 |
| テッセレータは非プログラマブルシェーダとして実装する? |
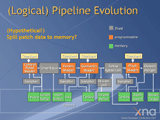 |
| 仮説的DirectX 11レンダリングパイプライン |
「あくまで現時点での“仮説的”(Hypothetical)なパイプラインだ」(Boyd氏)と断りを入れた上で、DirectX 11以降のパイプラインダイアグラムを公開した。
注目すべきは左端2つのブロックで、テッセレータが固定機能ユニットとして描かれており、その代わり、その前段階の「Control Point Shader」と呼ばれる新しいプログラマブルシェーダーが追加されていることがわかる。これは、ポリゴン分割の際の制御点をプログラマブルに制御するもので、テクスチャへのアクセス機能も与えられている。テッセレーション工程そのものは固定機能として与えられるが、テッセレーションのさせ方はプログラマブルに制御できる……と考えればわかりやすいだろう。
■ ついに「A-Buffer概念」の導入が検討される?
冒頭の(1)で指摘している、レンダリングした映像の品質に関しての向上について、DirectX 11以降でもまだまだやるべきことは多いという。
特に、描画順序に囚われない透明要素のレンダリング、そして未だにアンチエイリアスについても進化の余地はあるという。
 |
 |
| 半透明とアンチエイリアシング | |
描画順序の整列は未だに重い処理だし、マルチパスレンダリングとの整合性も取れなければならない。
こうした高度な要求に対し、DirectX 11以降では「A-Buffer」の概念の導入について検討を開始しているという。
現在のリアルタイム3Dグラフィックスでは、基本的には、最終的に見えるフレームだけを成形することを目的としているので、フレームバッファに書き込まれるピクセル色は基本的には上書きされていってしまう。その上書きをすべきか否かの判断を、Zバッファ(深度バッファ)に書かれた深度値を見て行なっている。フレームバッファ上には常に視点から見て最も手前にある「見える1ピクセル分」の情報しか描かれていないのだ。だから半透明の話が関係してくると、描画順序をしっかりしておかないと、本来は透けて見える後ろ側の情景が、切り捨てられて描画されなかったり、前後関係がおかしなことになって見えてしまう。
「A-Buffer」はジョージ・ルーカス率いるLucas Filmが考案したオフラインレンダリング向けのメソッドで,レンダリング時にシェーダで算出されたカラーの他に、輪郭のマスク情報や深度値情報などと一緒にフレームバッファに書き込んでいくもの。最終描画後にはつじつまが合うように映像を再構成する必要があるが、レンダリング時の描画順序の依存性を完全排除できるというメリットがある。複雑性を予見できないため、メモリを膨大に消費してしまうのだが、これをなんとかDirectX 11以降でリアルタイム実装できないか、検討が始まっているというのだ。実装には何レイヤー分までバッファするかとか、1ブロック何×何ピクセル管理にして各ブロック当たりの最大記録容量を想定してバッファする実装にするか、溢れたら切り捨てるのか、それともその時点で合成をするのか……とか、さまざまな検討が行なわれているようだ。
そして、このA-Bufferの仕組みをプログラマブル実装するのか、固定機能として実装するのか、という決断もしなくてはならない。その仕組みの素性からも想像できるように、高品位なアンチエイリアス処理が期待できるが、とはいえ、どういう実装が適しているのかも入念に検討する必要があるだろう。
なお、過去、NVIDIAのチーフサイエンティストのDavid Kirk氏にインタビューした際、同氏も「A-Bufferはいずれ実装の検討をしなければならないテクノロジー」と述べていた。
ここ数年、シェーダーユニット周りの強化ばかりが着目されてきたが、DirectX 11以降では、レンダリングパイプラインの最終パス部分について、大きな革新が行なわれるのかも知れない。
 |
 |
 |
| DirectX 11以降、A-Bufferの導入はありえるのか | ||
■ まとめ~プログラマビリティはどこまで必要なのか?
プログラマブルシェーダの概念が導入されてから以降、GPUはプログラマビリティ強化の進化の道を歩んできた。
DirectX 11以降も、この流れはゆるむことがないとされるが、ただ、どの要素をどうプログラマブルにしていくか、といった部分の議論は依然と熱い。
例えば、GPUの歴史の中でずっと固定機能として君臨しているものにトライアングルセットアップ/ラスタライゼーションのユニットがある。ここはポリゴンから、描画フレーム上のピクセルへの対応付けを行なう処理系だが、これをプログラマブルにしたいという要求があったりする。具体例で言えば、現在のトライアングルセットアップ/ラスタライゼーションではこのポリゴン→ピクセルへの対応付けを線形な直行座標系で行なっているが、これを対数座標系などで実装したいという要望があるのだ。これがあれば、シャドウマップ系の影生成メソッドの新しい手法として最近発表された対数シャドウマップの実装を容易にすることができ、なおかつパフォーマンスアップが期待できる。
ただ、「固定機能として実装されているからこそ高速」という側面もあり、何から何まで全部プログラマブル化してしまうと、パフォーマンスが犠牲になってくる場合も出てくる。また、固定機能としてあったものを排除した関係で、これまで固定機能ユニットに任せきりだった定番処理を自前でシェーダプログラムとして書かなければならず、それがまた面倒になってくる場合もある。例えばα合成の固定機能を排除したら、全てのピクセルシェーダプログラムで自前でα処理を用意する必要があり、これはこれで面倒なことになる。
固定機能のまま残すべきか否か……このあたりのせめぎ合いは難しいものがある。
 |
 |
| プログラマビリティ | |
さて、Windows Vistaの登場と、これに同期したDirectX 10の提供により、なんとなく、一般ユーザーの多くは「PCグラフィックス業界は1つのゴールに到達したのかな」という、やや満足じみた空気を感じとっていたかも知れない。ところが、次世代アーキテクチャを考えている最先端の現場では全然そんなことはなく、まだまだ、やるべきことは山積みで、そして進化のヘッドルームも無限大という認識となっているのが興味深い。
現在、“CPU屋さん”の方では、CPUとGPUを統合して、ネイティブ命令セットを実装してCPUとGPUのコンピューティングを統合化してはどうか、という議論までが始まっているが、“GPU屋さん”の方では、それどころか、新しいシェーダをまだ追加したり、あるいはパイプライン構造そのものを大改変しようと計画していたり、その温度差というか、向かおうとしている方向性に連帯感がないのが面白い(といっては失礼かも知れないが)。
なお、Boyd氏によれば、DirectX 11の登場時期や提供スタイルは全く未定としており、今回のプレゼンテーションで提示した未来のDirectX像については「あくまで仮説として受け取って欲しい」と述べていた。
□Game Developers Conference(英語)のホームページ
http://www.gdconf.com/
□Game Developers Conference(日本語)のホームページ
http://japan.gdconf.com/
□関連情報
【3月8日】Game Developers Conference 2007 記事リンク集
http://watch.impress.co.jp/docs/20070308/gdclink.htm
(2007年3月11日)
[Reported by トライゼット西川善司]
GAME Watchホームページ |
また、弊誌に掲載された写真、文章の転載、使用に関しましては一切お断わりいたします
ウォッチ編集部内GAME Watch担当game-watch@impress.co.jp
Copyright (c)2007 Impress Watch Corporation, an Impress Group company. All rights reserved.