
| ||||
|
3Dゲームファンのための「RADEON X800」講座 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
 |
 |
| RADEON X800イメージロゴ | RADEON X800カード | RADEON X800チップ |
 |
 |
 |
| RADEON X800シリーズの先行発表会は4月14日と15日の二日間の間にATI本社のあるカナダ・トロントで行なわれた | 「某社の最新鋭GPUのナンバーワンの地位はまたしても数週間しか保たなかった(笑)」と余裕のコメントで新RADEONを発表したRick bergman氏(SeniorVice President,General Manager,Desktop) | |
■ ピクセルレンダリングパイプラインは2倍、動作クロックは500MHz
ただし、プログラマブルシェーダバージョンは3.0には未対応!
 |
| RADEON X800系は上位のXTモデルとPROモデルが同時発表となった。ちなみにRADEON9800系も、ここしばらくは併売されていく見込みだという |
総トランジスタ数は約1億6000万トランジスタ。RADEON9800系が約1億2000万トランジスタだったのでNVIDIAのGeForce6800Ultraと比べるとおとなしめな伸び率ということになる。製造プロセスルールは銅配線Low-kの0.13μm。RADEON9600XTは世界最初のLow-k(低誘電体層間絶縁膜)を活用して製造されたプロセッサだったが、同時発表された上位モデルRADEON9800XTの製造には旧世代の0.15μmを使っていた。今回より、最上位モデルの製造においてもこの最新プロセスルールを使うことになったわけだ。
ちなみにLow-kとは微細な配線間に起こりうる信号干渉を低減するためのシーリング素材のこと。同じ微細度でもLow-k版の方が、強い電流を流さずに済み、ひいては高い省電力性能と高クロック動作が行なえるメリットがある。今回発表された新RADEONの上位モデルと下位モデルの基本公称スペックは、RADEON X800XTのコア500MHz以上、ビデオメモリ1GHz以上で、RADEON X800PROはコア475MHz、ビデオメモリ900MHzとなっている。プロセッサの規模が違うので一概には比べられないが、RADEON9800XT(412MHz)と比べて88MHzも高クロック動作が可能となったのは、さすがはLow-k/0.13μmといったところか。また、コア動作クロックだけで言えばGeForce6800Ultraよりも100MHz高い。
組み合わされるビデオメモリはGeForce6800Ultra同様のGGDR3 SDRAM。ビデオメモリバスはRADEON9800系からの据え置きの256bit幅。
プログラマブル頂点シェーダは6基構成、ピクセルレンダリングパイプラインは16本で全てのパイプラインがプログラマブルピクセルシェーダを持つ構成を取る。プログラマブル頂点シェーダは2基分増設、ピクセルレンダリングパイプライン及びプログラマブルピクセルシェーダは2倍に倍増されたことになる。
なお、注目されてきたプログラマブルシェーダーバージョンは意外にも2.0に据え置かれることが明らかにされた。細かいバージョンの詳細事項については後述するが、RADEON X800シリーズはプログラマブルシェーダ3.0仕様には未対応ということになる。
これについてATIは「RADEON9700/9800シリーズの貢献もあり、現在のリアルタイム3Dグラフィックス開発者にとってのプログラマブルシェーダの標準仕様は間違いなく"2.0"である。不用意に3.0へ進むことはせず、2.0仕様の成熟へいざなうことが、RADEON X800シリーズの使命だ。」と説明する。
 |
 |
| 「プログラマブルシェーダ2.0仕様には留まるべくして留まったのだ。」とアーキテクトを担当したBob Drebin氏(Director of Enginering) | ATIはハイエンドGPUにもLow-kプロセスを採用。動作クロックや省電力性能でNVIDIAに差を付ける |
 |
 |
| RADEON X800XTのブロックダイアグラム全体図 | 全体図を見ても分かるように、最初登場するRADEON X800系は、AGP8Xネイティヴ版。PCI-EXPRESSネイティヴ版も追って発表されると思われる |
■ 頂点シェーダは6基構成になり動的分岐/反復制御がサポート
バージョン番号はGeForceFXと同じ「2.0a」
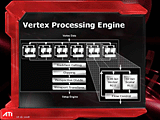 |
| RADEON X800XTのプログラマブル頂点シェーダのブロック図 |
各頂点シェーダユニットは128ビット(32ビット×4)の浮動小数点実数(FP)ベクトル演算器と、32ビットFPスカラ演算器の二段構えで構成され、実行に依存関係がなければ両演算器は並列動作が可能となっている。この構成自体はRADEON9800系と同じだ。
しかし、トータルパフォーマンスとしては、GPUコアの動作クロック上昇分が加味されて、RADEON9800XTの約二倍の毎秒7億5000万頂点毎秒の処理が可能となったという。頂点シェーダは前段でも述べているように、プログラマブル頂点シェーダ3.0仕様には対応していない。よってGeForce6系のような、頂点シェーダからのテクスチャ参照能力は搭載されていない。ただし、まったくRADEON9800系と同じかというとそういうわけでもなく、若干のマイナーチェンジが施されている。それが、ブロック図にも記載されている「分岐制御」(Flow Control)機能だ。
頂点シェーダの基本機能、命令セットこそバージョン2.0仕様に据え置かれているが、RADEON X800では、頂点シェーダプログラムの動的な分岐/反復制御が行なえるようになったのだ。状況やユーザー操作に応じた、高いインタラクティヴィティを備えた頂点シェーダプログラムが実行可能になる。RADEON X800系のDirect3D上における便宜上の頂点シェーダバージョンは「2.0a」というふうに区分され、これは丁度NVIDIAのGeForceFXシリーズと同等と言うことになる。
■ ピクセルシェーダは16基、バージョン番号は「2.0b」へ
演算精度は24ビット据え置き
RADEON X800XTのピクセルレンダリングパイプラインは16本構成、下位モデルのX800PROは12本構成になる。ATIは8本構成のモデルの用意もあるということをほのめかしたが具体的な製品名は明らかにされていない。これまでのネーミングの流れからすればX800SEとなる可能性が高いだろう。
各パイプラインは4本ごとに「クワッド」という形でまとめられており、テクスチャキャッシュやZバッファ処理ユニット、テンポラリレジスタ等はこのクワッド単位で共有化されている。なお、各クワッドは他のクワッドの処理進捗度に無関係に完全に独立して動作できる特徴を持つ。
なお、製造上の問題で万が一、レンダリングパイプラインの1本が正常に動作できないチップができあがったとしても、このパイプラインを含むクワッドを無効化するだけで、クワッド減にて動作できるチップが取れる。ちなみに、RADEON X800PROは3クワッド構成、X800SE(仮)は2クワッド構成ということになるわけだ。
 |
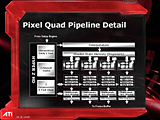 |
| RADEON X800XTのピクセルレンダリングパイプラインの概念図 | ピクセルレンダリングパイプライン4本単位で、いくつかのリソースを共有する設計。この4本単位のパイプラインを「クワッド」と呼んでいる |
さて、各ピクセルレンダリングパイプラインに含まれるピクセルシェーダユニットは、プログラマブルピクセルシェーダのバージョンは3.0にこそ対応していないものの、RADEON9800系と比較してかなりの改良が施されている。
まず、シングルパスで実行できる命令の数がRADEON9800系の160個から1536(512×3)個へと拡張された。1536個の内訳は、ベクトル演算が512個(RADEON9800系では64個)、スカラ演算が512個(RADEON9800系では64個)、テクスチャ処理が512個(RADEON9800系では32個)となる。もちろん、これは、RADEON9800系から搭載されたFバッファ機能を活用した上でのことになるが、Fバッファのメモリマネージメントが洗練されたことにより、実効パフォーマンスは向上しているという。
なお、冒頭でも述べているようにRADEON X800のプログラマブルピクセルシェーダ仕様はバージョン3.0未対応であり、動的分岐/反復制御には対応していない。RADEON X800系のプログラマブルピクセルシェーダは、イメージ的にはRADEON9800系のバージョン2.0の命令数制限を緩和したものであり、Direct3Dにおける便宜上のバージョン番号は「2.0b」となるようだ。なお、ATIはこのRADEON X800系のシェーダアーキテクチャを「Smart Shader HD」と命名している。ちなみに「2.0a」はGeForceFX系のプログラマブルピクセルシェーダのバージョン番号だ。
さて、仕様的にはマイナーチェンジの印象が強いものの、ハードウェア的にはなかなか豪勢な改良が施されている。RADEON9800系ではそれぞれ1基ずつだった各ピクセルシェーダユニットに含まれる3要素ベクトル(xyz)FP演算器とスカラFP演算器は、RADEON X800系では、それぞれ2基ずつ、2倍に増えている。
しかも「依存関係がない場合には2個のベクトルFP演算、2個のスカラFP演算、1個のテクスチャアドレッシング命令が全て並列動作できる。」(Bob Drebin氏)としており、ピクセルシェーダユニット単体のスループットでいけば、GeForce6800Ultraよりも並列動作性能は優れていることになる。複雑で長いピクセルシェーダプログラムを実行させた場合にはRADEON X800系の方が高いパフォーマンスを発揮するかもしれない。
 |
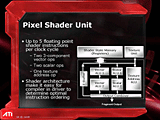 |
| GeForce6800Ultraのピクセルシェーダにはシェーダユニット#1と#2があり並列動作が可能な設計になっているが、シェーダユニット#1とテクスチャユニットが排他動作になる制約があり、その並列動作性は限定的だ。これに対し、RADEON X800系のピクセルシェーダユニット内のテクスチャユニットと4つのFP演算器が依存関係がなければ並列動作できる | |
さて、シェーダユニットのFP演算精度についてだが、これは今世代もRADEON系は24ビット精度を採用することが明らかとなった。ATIはこれについて「現行、DirectX9世代におけるリアルタイム3Dグラフィックスのピクセル陰影処理精度は24ビットで必要十分と考えているため」と説明している。今世代においてもGeForce対RADEONの戦いは、32ビット対24ビットの構図に置き換えられて議論されることになりそうだ。
■ 法線マップを高精度に4:1へ圧縮する仕組み「3Dc」機能搭載
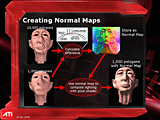 |
| 多ポリゴンでモデリングしたキャラクタのディテールをバンプマッピングに落とし込む……という概念図。実際には少ポリゴンでも、バンプマッピングでディテールを貼り付けたモデルは見た目的には多ポリゴン |
PCの3Dゲームファンの多くが「バンプマッピング」をご存じだと思う。最終的に得られる効果だけを簡単に言えば、3Dcはバンプマッピングを高精度で美しくするための機能……ということになる。
本来、デコボコというのは頂点(ジオメトリ)情報を用いてポリゴンで表現するのが"筋"なのだが、あまりにもその凹凸が微細な場合は、ポリゴンで表現しても演算パワーだけ消費して見た目的に割が合わない。そこで、ポリゴンを構成するピクセルに対し、あたかも凹凸があるかのように陰影処理を行なってやることで「見た目的な凹凸の質感」を与える3Dグラフィックス技術がバンプマッピングだ。
バンプマッピングには、その凹凸を構成する微細な面の向きを表すベクトル…すなわち「法線ベクトル」(Normal Vector)をテクスチャ化したものを使用する。これを特に「法線マップ」(Normal Map)と呼ぶ。
法線マップはテクスチャとして扱われるが、テクスチャマッピングの際に取り出したテクセルは"画素"としてポリゴンに貼り付けられるのではなく、「法線ベクトル」(ベクトルデータ)として取り扱われ、バンプマッピングを行なうピクセルシェーダプログラムによって陰影処理されて、その結果が描き込まれることになる。つまり、法線マップはテクスチャの体裁は取るものの、その中身は画像ではなく数値データなので、普通に非可逆圧縮してしまうと、精度が落ちてしまうのだ。
テクスチャの非可逆圧縮といえば、DirectXに規定されているDXTC(DirectX Texture Compression)と呼ばれる規格がある。GPUマニアならば、これがS3が開発したテクスチャ圧縮技術「S3TC」がベースになっていることはご存じかもしれない。画像テクスチャをDXTC(S3TC)で圧縮しても見た目的にほとんど変わらないのだが、法線マップを、DXTCで圧縮してしまうと微細な凹凸感が完全に破損してしまう。
 |
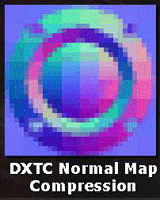 |
 |
| 無圧縮の法線マップを可視化したもの。なお、RGBにそれぞれ法線ベクトルのXYZの各値が入ってい | 法線マップをDXTC圧縮した場合。普通は法線マップをDXTC圧縮しない。DXTCは画像圧縮のための技術なので劣化がひどい | 無圧縮のオリジナルと見比べると劣化しているのは分かるが、それにしてもDXTCと比べれば圧倒的に3Dcの方が高品位だ |
「TOMBRAIDER 美しき逃亡者」「DeusEx:InvisibleWar」「FarCry」「Halo」「Serious Sam2」「SplinterCell:PANDORA TOMORROW」などなど、最近は法線マップを当たり前のように使う3Dゲームが激増しているが、前述のような問題点があるために、多くの近代PC-3Dゲームでは、この法線マップをDXTC圧縮せずに無圧縮状態で活用しているのだ。ところがこれでは多大ビデオメモリを必要とする。
そして、この問題を解消するために提供されたのが「3Dc」というわけだ。なお3Dcも圧縮アルゴリズム自体は非可逆系なので劣化はする。が、ベクトルデータのための非可逆圧縮なのでDXTCとは違って数値の意味に配慮したアルゴリズムになっているのが特徴だ。
そのアルゴリズムを簡単に解説しておこう。無圧縮法線マップはαRGB各8ビットで構成されるテクセルのRGBに、法線ベクトルのXYZを割り当てることが多い。αチャンネルは未使用なので無駄であり、これをまずカットして詰める。これでデータ量は3/4になる。
法線ベクトルは、面の向きの情報しか必要ないためにベクトルの大きさ自体は不要であり、正規化しても問題ない(絶対値1)。正規化したベクトルは、例えば、X,Yだけデータ化すればよく、Zはカットできる。これでデータ量は2/4、半分になる。ちなみにバンプマッピングを実際に行なう陰影処理の際にはZは法線マップから取り出したX,Yから計算で求めればいいのだ。
3Dcではさらに4×4、16テクセルに格納される法線ベクトルに対して、X,Yの最大値とX,Yの最小値を取り出し、これを8ビットでデータ化し、16テクセル分のXとYの値は、その最小値、最大値の間のどの辺りの数値か……ということを3ビットずつで表現する。X&Yのコード(6bit)×16(テクセル)+XYの最小値&最大値(8×4)=128bit。無圧縮だと32bit×16(テクセル)=512bitのところが、128bitで済むので圧縮率1/4という話になるのだ。
 |
 |
| 無圧縮法線マップはこのようにαRGBのRGB要素に対して法線ベクトルのXYZを格納している。4x4テクセルで512ビットの情報量があることになる | これを圧縮して128ビットの大きさ、すなわち1/4にしてしまうのが3Dc |
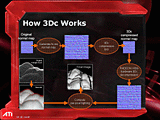 |
| 3Dcを利用する際の模式図 |
3Dcの圧縮処理がソフトウェア処理だとすれば、RADEON X800自体は、3Dcのなにをどうハードウェアサポートしてくれるのか。それは、そのテクセルのアクセス時だ。この3Dcの一種独特なフォーマットを配慮したテクスチャアドレス計算が行なわれ、X,Yの法線ベクトルデータをちゃんと読み書きしてくれるのだ。ちなみにZの値は、プログラマブルピクセルシェーダで2命令ほど使って自力で逆算公式で求める必要がある。
3Dc機能というと仰々しいが、仕組みとロジック自体は意外に単純なものだ。とはいえ、その効果は大きく、ビデオメモリ容量制約を気にせずに高精度なバンプマッピングが出来るようになるために、ビジュアル的な表現力は各段に向上する。
単純ながら効果の大きいアイディアであるため、3Dゲーム開発者達からの標準化を叫ぶ声もあり、現在マイクロソフトと協議し次期DirectXでの標準仕様への組み込みも検討されているとのことだ。
実際の対応アプリケーションとしては、RADEON9800XT発表以来、ATIとの関係が深いValveが放つ注目作「HalfLife2」が挙げられている。発表会では、実際にHalfLife2エンジンのRADEON X800カスタマイズ版やSerious Sam2のRADEON X800カスタマイズ版を用いて3Dcの効果を示して見せた。
 |
 |
| 「HalfLife2」より。法線マップをDXTC圧縮した時のレンダリング結果 | 法線マップを3Dc圧縮した時のレンダリング結果。水面のさざ波の出方が違うのは辛うじて分かるが、明るい場所で映したプロジェクタの映像を撮影した写真であるためにちょっと分かりにくい |
 |
 |
| 左が3Dcで圧縮された高精細法線マップによる凹凸。右が低精度法線マップによる凹凸。3Dcを使えば法線マップを1/4に圧縮できる。これはすなわち、逆に、同じ容量の法線マップで高精細な凹凸表現が出来るということ | |
 |
 |
| RADEON X800の専用イメージデモ「RUBY」はCM映像などを手がける3D-CG制作スタジオRhinoFXとの共同制作による。このクオリティの映像がリアルタイムで動作するが、男性のシワ、女性のコスチュームのディテール感は3Dcの効果によるものだ | |
■ その他の機能
この他、RADEON9800系に搭載されていた独自機能が、マイナーチェンジという形でバージョンアップしている。
●Hyper Z HD
 |
| HYPER Z HDは基本的にRADEON9800系からの大きな改変はない |
●Temporal Anti-Aliasing
 |
| Temporal Anit-Aliasingの概念図。ATIは「ディスプレイのリフレッシュレートよりも、フレームレートの方が高い場合に有効な効果」と説明しており、この条件に当てはまらないときには、狙った画質にならない可能性がある |
これを概念図で示した図が右図で、たとえば、2Xサンプルモードであっても、連続した映像を見る限りでは4Xサンプルモードの効果に相当する映像が得られる…というわけだ。サンプル数が少なければ少ないほどパフォーマンスの低下が少なく、サンプル数が多ければ多いほど高精度なアンチエリアスが実現されるので、丁度このモードは、ハイパフォーマンスと精度の高いアンチエリアス効果の両立を狙ったもの……ということになる。
■ まとめ~RADEON対GeForceの戦いはスタート&ダッシュで決まるのか?
新RADEONがプログラマブルシェーダ3.0仕様への対応を見送ったことにより、プログラマブルシェーダ3.0仕様は当面はNVIDIAのGeForce6800系(GeForce6系)独自の仕様となる。これは立場こそ逆転しているが、かつてATIがRADEON8500登場と同時に打ち出した新仕様「プログラマブルピクセルシェーダ1.4」に、NVIDIAが後発のGeForce4Tiでは対応を見送った状況によく似ている。実質的にGeForce4Tiは「先代GeForce3の高性能版どまり」という位置付けだったわけだが、結果として、GeForce4TiはRADEON8500よりも「製品としては」成功を収めた。
RADEON X800系は、RADEON9800系の高性能版であり、RADEON9700/9800の成功を引き継ぐことに注力した製品になるわけなのだ。結局のところ、RADEON X800系が成功するかどうかは、今後のアプリケーションの動向にかかっている。登場してくるソフトウェアが、プログラマブルシェーダ2.0仕様に留まるのであれば、クロックが高い分、パフォーマンス的には上をいくRADEON X800系が有利に事を運ぶだろう。しかし、プログラマブルシェーダ3.0仕様を積極的に活用したソフトウェアが出てきた場合には、これに対応できないRADEON X800系は不利になる。果たして今回のATIの決断は吉と出るか凶と出るか、その行く末はいろんな意味で興味深いところである。
さて、今回、RADEON X800シリーズはXTとPROの両モデルが同時に発表されたものの、リリース時期は若干ズレが設定される。下位モデルのRADEON X800PROは、5月4日以降に随時店頭に並ぶ予定で、上位のRADEON X800XTは5月21日以降となっている。価格は未定としながらも、「先代のRADEON9800XTや同PROの価格から大きく逸脱はしない」としている。
あのスペックから、見るからに、聞くからに高くなりそうなNVIDIA GeForce6800Ultraと比べて、確かにRADEON X800系は「我々の想像からそれほど逸脱しなさそうな価格にはなりそう」というイメージだけは伝わってくる。
価格とリリース時期。もしかすると、この2つの問題は、シェーダバージョン問題よりも重要で、両者の戦いのスタート&ダッシュの勢いを決定づける要因となるかもしれない。
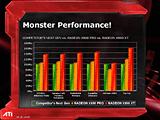 |
 |
 |
| ATI調べのパフォーマンス比較グラフ。緑のバーは当然のごとくNVIDIAの新鋭「GeForce6800Ultra」を指しているのは言うまでもない | 実際に動作するATIリファレンスデザインのRADEON X800XTカード。カードの大きさはRADEON9800系とそう大差はない。電源コネクタは1基のみ。クーラーの背丈も低いのでAGPスロットしか占有しない | |
□ATI Technologyのホームページ のホームページ
http://www.ati.com/
(2004年5月5日)
[Reported by トライゼット西川善司]
GAME Watchホームページ |
また、弊誌に掲載された写真、文章の無許諾での転載、使用に関しましては一切お断わりいたします
ウォッチ編集部内GAME Watch担当game-watch@impress.co.jp
Copyright (c) 2004 Impress Corporation All rights reserved.
|
|